多类逻辑回归
1.其实就是一个多分类问题,用到softmax函数:将每一项变为非负,然后归一化每一项得到一个概率。(softmax虽然简单但是手写存在一点问题,当输入过大,出现NAN,除此之外易造成数值的不稳定)
2.另一种针对预测为概率值的损失函数—-交叉熵损失函数,关于交叉熵函数的详解.将两个概率的负交叉熵作为目标值,最小化这个值等于最大化这两个概率的相似度(预测概率和真实概率)。
3.数据集采用的FashionMnist,讲道理Mnist被用烂了吧。
4.关于FashionMnist的下载问题。换下载地址。vision.py,需要改的部分上截图。下拉到文底
下载数据,制作数据迭代集
transform 对数据进行归一化,类型转换,用gluon制作数据迭代集1
2
3
4
5
6
7from mxnet import ndarray as nd
from mxnet import autograd as ag
from mxnet import gluon
def transform(data,label):
return data.astype('float32')/255,label.astype('float32')
mnist_train = gluon.data.vision.FashionMNIST(train=True,transform=transform)
mnist_test = gluon.data.vision.FashionMNIST(train=False,transform=transform)
设置输入维度和输出维度,为参数申请梯度空间
1 | num_inputs = 784 |
多分类函数
这是低级版的softmax,可以有一些优化
也可以理解为对计算结果的值域限制1
2
3
4def softmax(a):
exp = nd.exp(a)
partition = exp.sum(axis=1,keepdims=True)
return exp/partition
网络计算
1 | def net(x): |
交叉熵损失函数(针对概率值的损失函数)
1 | def cross_entropy(yhat,y): |
优化函数
1 | def SGD(params,lr): |
计算准确率和evaluate_accuracy
这里的output是一个矩阵,第一维度是batch_size
这里的argmax返回output每行中最大值的索引
asscalar将nd.mean的结果转为标量
1 | def accuracy(output,label): |
训练(打印没训练的模型准确率作为参考,一般接近10%)
1 | print('Not train ,the result',evaluate_accuracy(test_data,net)) |
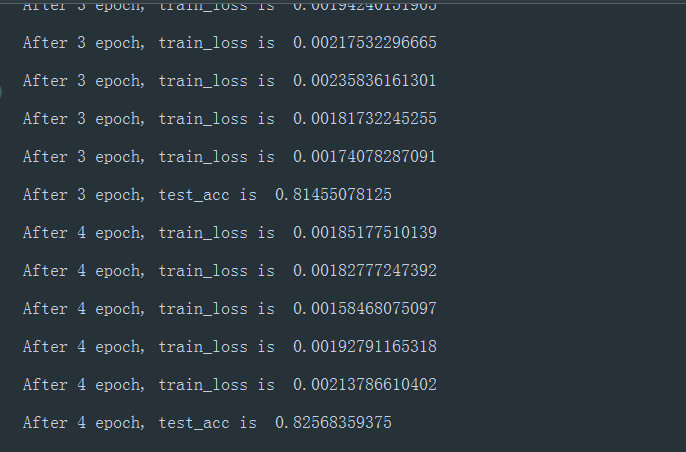
截图
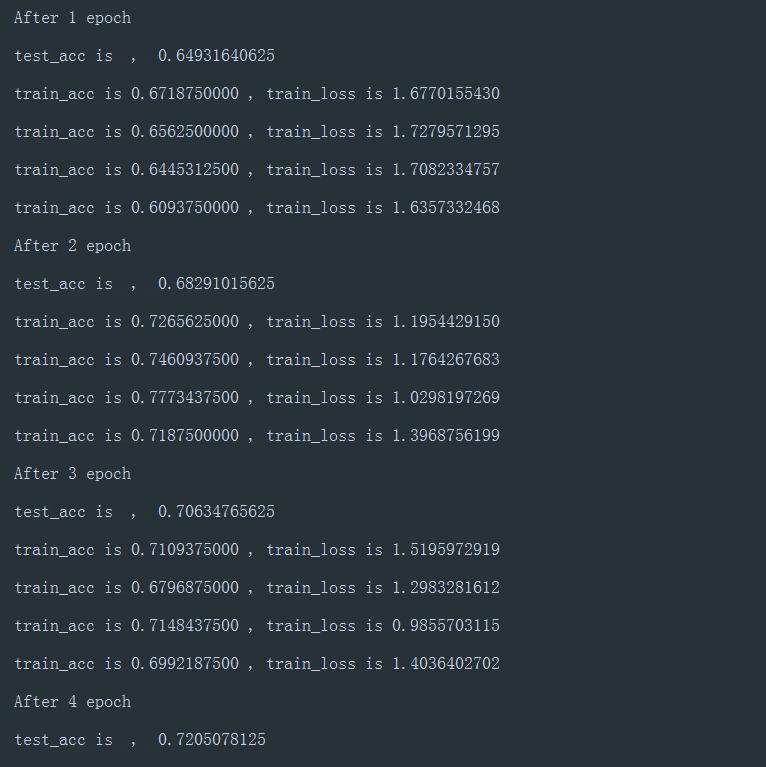
继续研究softmax问题
关于FashionMnist如何下载问题,下面提供自己的解决方案
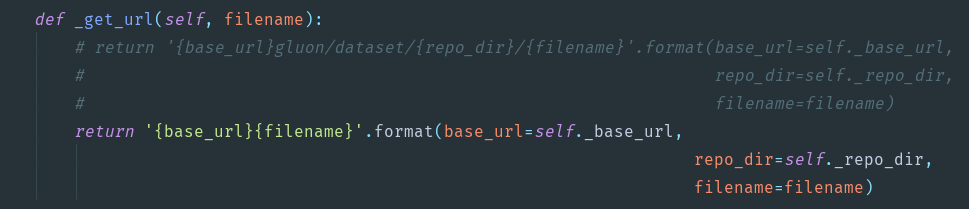

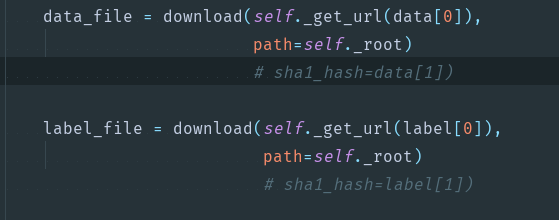
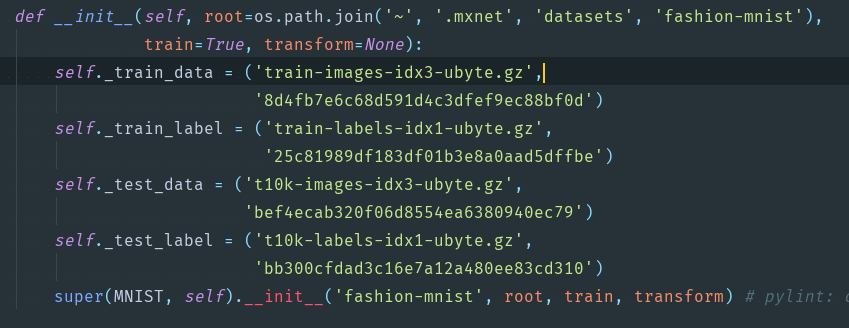
不加解释上Gluon版本,识别率居然比自己写的高10个百分点,那是什么原因。
1 | from mxnet import ndarray as nd |
补充
- 上面的softmax中会发生上溢出和下溢出,可以想象当x很大时,exp(x)会出现NAN情况,显然是不想看到的,可以用平移的思想。exp(x-max(X)),这样会用0取代先前的NAN。可是这还不是理想的状态…
- 机器学习中的训练其实是对损失函数(loss function)的优化。
- 分类问题中,一般使用最大似然估计来构造损失函数。最大化似然函数等同于最小化对数似然。
- 相对熵和交叉熵。交叉熵反映了p,q之间的相似程度。
- 对于分类问题,对数似然和交叉熵损失函数是等价的。