计算机中的神经网络是研究者试图通过人工模拟脑神经元作为学习模型,但是这种模型通过梯度下降来学习,不得而知人脑应该不是这样学习的吧。这块恐怕还需要生物学家做出贡献,才能进一步提升或者说优化神经网络的学习能力。时代造英雄,深度神经网络的崛起不是偶然,随着海量的数据,计算能力更强的硬件支撑,深度神经网络开始展现它强大的学习能力。为什么从Alex Net说起,本人觉得是一个分界线,Alex Net相比之前的网络更大,参数更多,当然取得更好的效果,完胜传统的机器学习方法(ImageNet)。
下面简单说下图像方面的几个模型,旨在了解每个网络模型的特点,优点,以及构造的思路。Alex Net
八层转换:五层卷积,两层全连接,一层输出层。具体的每层的设计看代码(卷积核的大小,池化层的设计)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
net = nn.Sequential()
with net.name_scope():
net.add(
# 第一阶段
nn.Conv2D(channels=96, kernel_size=11,
strides=4, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2),
# 第二阶段
nn.Conv2D(channels=256, kernel_size=5,
padding=2, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2),
# 第三阶段
nn.Conv2D(channels=384, kernel_size=3,
padding=1, activation='relu'),
nn.Conv2D(channels=384, kernel_size=3,
padding=1, activation='relu'),
nn.Conv2D(channels=256, kernel_size=3,
padding=1, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2),
# 第四阶段
nn.Flatten(),
nn.Dense(4096, activation="relu"),
nn.Dropout(.5),
# 第五阶段
nn.Dense(4096, activation="relu"),
nn.Dropout(.5),
# 第六阶段
nn.Dense(10)
)
VGG
VGG是有重复结构网络。可以用for loop来快速搭建一个深层次的神经网络。VGG还有一个关键使用很多个3x3的卷积层接上一个池化层。for loop这样的结构。
通用结构
1 |
|
stack通用结构
1 | def vgg_stack(architecture): |
VGG11
8个卷积层,加3个全连接层1
2
3
4
5
6
7
8
9
10
11
12
13num_outputs = 10
architecture = ((1,64), (1,128), (2,256), (2,512), (2,512))
net = nn.Sequential()
# add name_scope on the outermost Sequential
with net.name_scope():
net.add(
vgg_stack(architecture),
nn.Flatten(),
nn.Dense(4096, activation="relu"),
nn.Dropout(.5),
nn.Dense(4096, activation="relu"),
nn.Dropout(.5),
nn.Dense(num_outputs))
Network in Network
NiN的出现对后面的Googlenet,resnet都有很大的影响。
沐神说林敏也是早期mxnet的开发者。感叹大牛身边还是大牛!
一个卷积操作理解成一个CNN感受野,传统卷积层可看成是一个广义的线性模型。当接收到的感受野(提取到的特征是线性可分的情况)CNN层对特征的抽象就足够了,但是要提取更加抽象的特征需要对输入的数据做高度的非线性变换。如何去做?1.同一层中对个通道来覆盖。2.stack多个CNN层来获取更抽象的特征。随之带来的问题也是显而易见的:参数太多,计算量太大。NiN就是用来解决这个问题。在正常卷积的基础上先用一个ksize为1的CNN层,效果等同对前一层的特征进行线性组合,也等同于一种全“连接层”。再使用激活函数进行非线性变换,这样并不能做到高度抽象提取。NiN又加了同样的ksize为1的CNN层,这样进一步提取达到高度的非线性转换。回过头看这两层CNN,就相当于在减少参数的情况下,做了两层“全连接”,实现特征的高度整合。
1.NiN两大特性:
mlpconv
平均池化层
2.作用:
实现跨通道的交互和信息整合
进行卷积核通道数的降维和升维,减少网络参数。
更直观的数学解释。
conv + conv(1x1) + conv(1x1) = mlpconv
1 | from mxnet.gluon import nn |
NiN的卷积层的参数
11x11,channel 96
5x5 ,channel 256
3x3 ,channel 384
另一个更有意思的地方是:NiN最后没有使用全连接,而是使用通道数为输出类别个数的mlpconv,外界一个平均池化层将每个通道的数值平均成一个标量。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
net = nn.Sequential()
# add name_scope on the outer most Sequential
with net.name_scope():
net.add(
mlpconv(96, 11, 0, strides=4),
mlpconv(256, 5, 2),
mlpconv(384, 3, 1),
nn.Dropout(.5),
# 目标类为10类
mlpconv(10, 3, 1, max_pooling=False),
# 输入为 batch_size x 10 x 5 x 5, 通过AvgPool2D转成
# batch_size x 10 x 1 x 1。
# 我们可以使用 nn.AvgPool2D(pool_size=5),
# 但更方便是使用全局池化,可以避免估算pool_size大小
nn.GlobalAvgPool2D(),
# 转成 batch_size x 10
nn.Flatten()
)
说了半天其实并没有看NiN的论文,期待开学对NiN有一个更加深刻的认识。没有详细上代码也是因为穷,没有gpu实在没法调参。
GoogLeNet
先来一张很吓人的图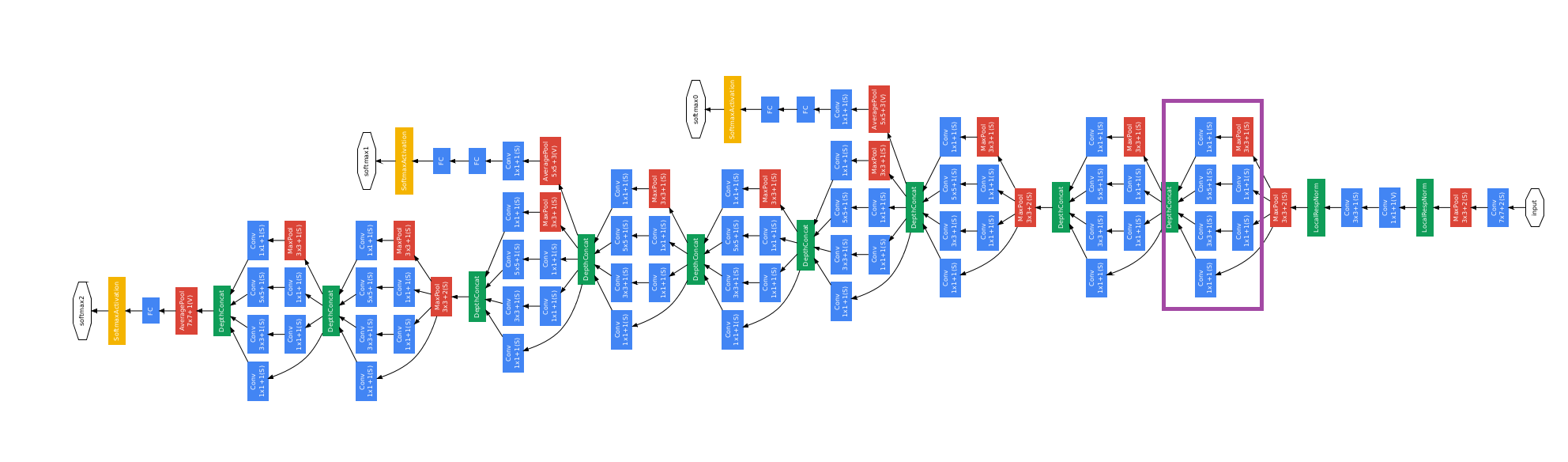
Inception
在NiN的思想上做了很大改进,一个Inception由四个并行卷积层组成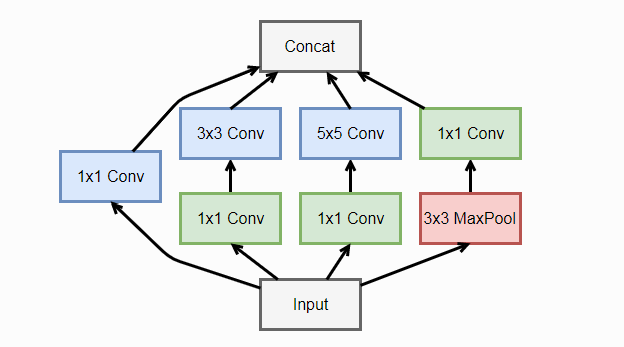
代码构造上图网络1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31from mxnet.gluon import nn
from mxnet import nd
class Inception(nn.Block):
def __init__(self, n1_1, n2_1, n2_3, n3_1, n3_5, n4_1, **kwargs):
super(Inception, self).__init__(**kwargs)
# path 1
self.p1_conv_1 = nn.Conv2D(n1_1, kernel_size=1,
activation='relu')
# path 2
self.p2_conv_1 = nn.Conv2D(n2_1, kernel_size=1,
activation='relu')
self.p2_conv_3 = nn.Conv2D(n2_3, kernel_size=3, padding=1,
activation='relu')
# path 3
self.p3_conv_1 = nn.Conv2D(n3_1, kernel_size=1,
activation='relu')
self.p3_conv_5 = nn.Conv2D(n3_5, kernel_size=5, padding=2,
activation='relu')
# path 4
self.p4_pool_3 = nn.MaxPool2D(pool_size=3, padding=1,
strides=1)
self.p4_conv_1 = nn.Conv2D(n4_1, kernel_size=1,
activation='relu')
def forward(self, x):
p1 = self.p1_conv_1(x)
p2 = self.p2_conv_3(self.p2_conv_1(x))
p3 = self.p3_conv_5(self.p3_conv_1(x))
p4 = self.p4_conv_1(self.p4_pool_3(x))
return nd.concat(p1, p2, p3, p4, dim=1)
需要注意的是Inception 将并行的卷积结果concat,显然不同卷积后的输出维度应该相同,需要用padding处理。Inception的版本有很多,日后再来补充。
ResNet
经过前面卷积神经网络模型我们了解到,网络宽不如网络深效果来的好。那么深的网络也会带来一个问题,不好训练。原因是:误差反传过程中,梯度通常会变的越来越小,权重更新量也会变小。可以理解为远离输出层的参数更新慢,甚至停止更新。ResNet通过跨层连接来解决梯度逐层回传变小的问题。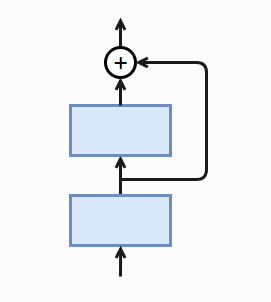 如图所示最底层的输入不仅输出给了中间层,还与中间层结果相加进入最上层。梯度反传时,嘴上才能梯度可以直接跳过中间层传到最下层(不是很明白这里的直接跳过,中间层不算梯度吗?为什么不是同时更新),避免最下层梯度过小。
如图所示最底层的输入不仅输出给了中间层,还与中间层结果相加进入最上层。梯度反传时,嘴上才能梯度可以直接跳过中间层传到最下层(不是很明白这里的直接跳过,中间层不算梯度吗?为什么不是同时更新),避免最下层梯度过小。
Residual块
1.沿用VGG 3x3卷积核,在卷积和池化层之间加入批量归一层加速训练。
2.每次跨层连接跨过两层卷积。
3.补充:当输入通道数和输出通道不一样时可选择1x1来做通道变化,同时strides=2把长宽减半。
Residual code
1 | from mxnet.gluon import nn |
构建ResNet
code中没有用个池化层来减少数据长宽,而是通过Residual中strides为2的卷积层。这里用18层演示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50class ResNet(nn.Block):
def __init__(self, num_classes, verbose=False, **kwargs):
super(ResNet, self).__init__(**kwargs)
self.verbose = verbose
# add name_scope on the outermost Sequential
with self.name_scope():
# block 1
b1 = nn.Conv2D(64, kernel_size=7, strides=2)
# block 2
b2 = nn.Sequential()
b2.add(
nn.MaxPool2D(pool_size=3, strides=2),
Residual(64),
Residual(64)
)
# block 3
b3 = nn.Sequential()
b3.add(
Residual(128, same_shape=False),
Residual(128)
)
# block 4
b4 = nn.Sequential()
b4.add(
Residual(256, same_shape=False),
Residual(256)
)
# block 5
b5 = nn.Sequential()
b5.add(
Residual(512, same_shape=False),
Residual(512)
)
# block 6
b6 = nn.Sequential()
b6.add(
nn.AvgPool2D(pool_size=3),
nn.Dense(num_classes)
)
# chain all blocks together
self.net = nn.Sequential()
self.net.add(b1, b2, b3, b4, b5, b6)
def forward(self, x):
out = x
for i, b in enumerate(self.net):
out = b(out)
if self.verbose:
print('Block %d output: %s'%(i+1, out.shape))
return out
DenseNet
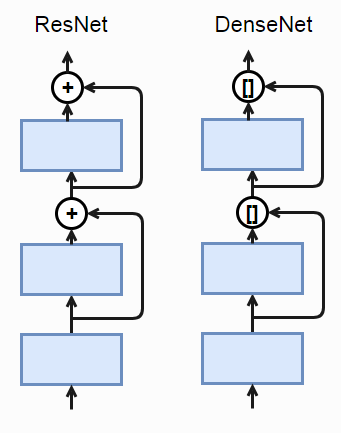
DenseNet的想法来自于ResNet,从图中可以看出将+,变为concat,也就是底层的输出会保留到更深层次。
稠密块
相比于ResNet,DenseNet卷积使用的版本BN->Relu->Conv.code中的growth_rate表示每个卷积的输出通道,in_channels表示输入,layers表示层数,输出通道数就是in_channels+growth_rate*layers。
Dense Block
1 | from mxnet import nd |
Transition Block
concat会使通道数激增,为了控制模型复杂度,引入过渡块,把输入的长宽减半,同时使用1x1卷积来改变通道数。1
2
3
4
5
6
7
8
9def transition_block(channels):
out = nn.Sequential()
out.add(
nn.BatchNorm(),
nn.Activation('relu'),
nn.Conv2D(channels, kernel_size=1),
nn.AvgPool2D(pool_size=2, strides=2)
)
return out
DenseNet构建
交替串联稠密块和过度块。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33init_channels = 64
growth_rate = 32
block_layers = [6, 12, 24, 16]
num_classes = 10
def dense_net():
net = nn.Sequential()
# add name_scope on the outermost Sequential
with net.name_scope():
# first block
net.add(
nn.Conv2D(init_channels, kernel_size=7,
strides=2, padding=3),
nn.BatchNorm(),
nn.Activation('relu'),
nn.MaxPool2D(pool_size=3, strides=2, padding=1)
)
# dense blocks
channels = init_channels
for i, layers in enumerate(block_layers):
net.add(DenseBlock(layers, growth_rate))
channels += layers * growth_rate
if i != len(block_layers)-1:
net.add(transition_block(channels//2))
# last block
net.add(
nn.BatchNorm(),
nn.Activation('relu'),
nn.AvgPool2D(pool_size=1),
nn.Flatten(),
nn.Dense(num_classes)
)
return net