目标检测
一直觉得,图像分类比较简单,物体检测多分类很复杂,所以也不愿意花时间去研究。万事开头难,每个人都有自己擅长的学习方式,而我喜欢:细究一样东西前,先整体把握。so,这篇博客先整体上了解一下目标检测的几个算法,算法出现前后优化了什么,解决了什么样的局限性。
目标检测:分析图片里有什么,然后识别它在什么位置。就是常见的一张图中一个框(bounding box),并给出概率。
R-CNN
思想:
1. Selective Search选出候选区域。
2. Conv抽取特征。
3. 分类器分类,回归器的得到准确bounding box。
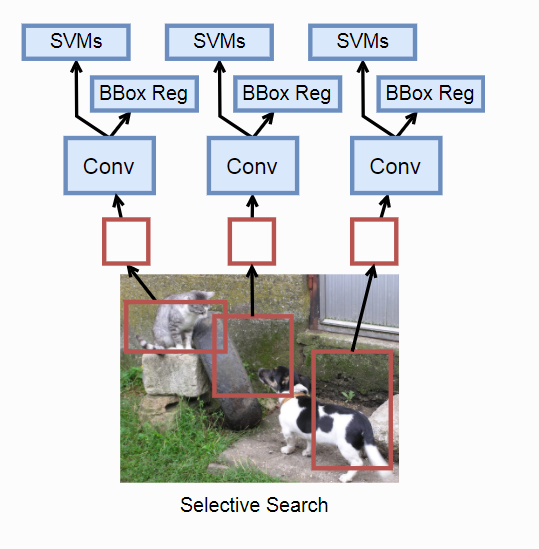
Tips:
1. Selective Search基于规则的选择性搜索。
2. 这边的特征提取可以用迁移学习微调。
3. 提取的特征放入多个svm分类器,每个svm判断是否包含这个物体。
4. 2提取的特征来训练回归器,得到bounding box。
缺陷:
Selective Search 可能选出上千个候选区域,速度特别慢。
Fast R-CNN
思想:
1. R-CNN的对原始图片进行Select Search,其中大量区域可能相互覆盖,每次可能抽取相同特征。Fast R-CNN解决办法是先对输入图片抽取特征,然后再选取区域
2. R-CNN使用多个SVM分类,太笨重。Fast R-CNN使用一个多类逻辑回归-Softmax。
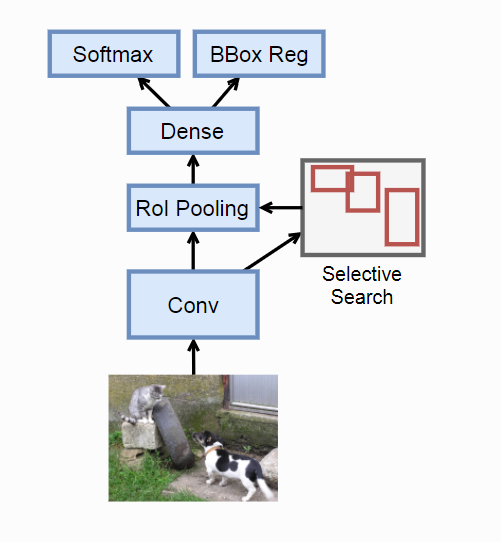
Tips:
1. 原始图片做一次特征提取,节省重复计算。
2. ROL(兴趣区域池化层)对指定区域池化,生成固定大小输出。(具体实现可以看后面博客)
Faster R-CNN
思想:
1. Fast R-CNN仍然是用Select Search来选取候选区域。Faster R-CNN改进提出了RPN选取候选区域。
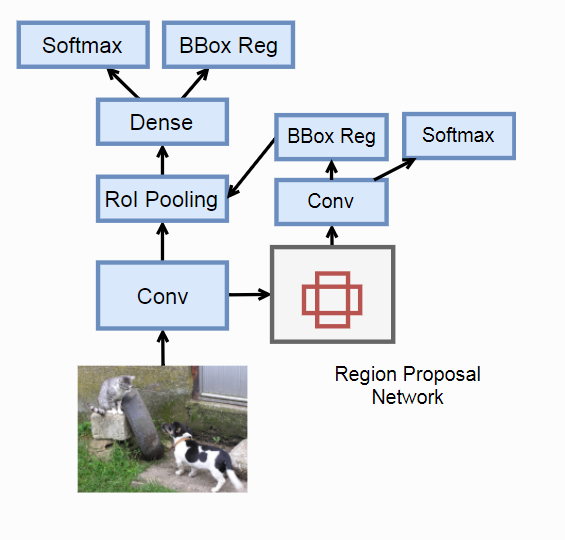
Tips:
RPN:
1. 预先配置好一些区域
2. 网络判断区域是否包含检测物体,如果是再预测一个更加准确的边框。
PRN具体操作:
1. 生成锚框。(以每个像素为中心,生成指定k个长宽比预先设定好的默认边框)
2. 构造分类器特征。例如输入特征基础上放一个padding为1,通道256的3x3卷积。得到长为256的向量。
3. 对于所有锚框,使用中心像素对应的256维向量作为特征放入分类器。被检测物体的,将回归器的边框作为输入放到接下来的ROL池化层。
SSD
思想:
1. 直接使用一个n+1个分类器。(n表示原有分类,1表示背景),并且直接使用一个回归器来预测bounding.
2. 不仅对卷积后的特征做预测,还会进一步将特征卷积再次预测。
Tips:
1. SSD单发多框检测器。所谓单发指的是不同于R-CNN候选区域和分类分开进行。