DCGAN AND WGAN
前言(废话)
今天有个孩子说我好几天没更新了。转念一想,虽然断断续续地完善前一篇GAN也并不是无所作为,但也不能给别人博主很懒的印象啊。再一想,自己当初写博客的目的只是为了记录自己的学习,提出困惑,谈谈自己的理解。可能更多的‘草稿’作用而非教学意义。可,可…也是时候重新开一篇把国庆看的东西好好整理一哈(其实一般是为了整理思路给明天的英文周报)。
DCGAN
1.为什么要有DCGAN?
Deep Convolutional Generative Adversarial Network可以从两个方面来说DCGAN为什么会被提出。首先,CNN在监督学习中取得了非常大的成功,无论是在图像分类还是目标检测任务中。那么在非监督学习中,一些人会蠢蠢欲动,是否也能取得不错的效果呢?其次,GAN网络的提出,掀起了generating model 的热浪,然而在上一篇文章中已经分析了GAN网络存在的一些问题。DCGAN能够从网络架构的角度一定程度上解决这个问题。关于GAN的问题,还会在接下来的WGAN的文章中详细解释。
2.DCGAN 相比GAN有什么改进的地方?
其实就是充分利用CNN的特点,对卷积网络拓扑做了一些限制,从而使得GAN的训练变得稳定一些。虽然论文里面还说了利用Discriminator做分类任务啊,可以visualize filters学习到了啥,甚至还有一些语义层面的。个人觉得,最大的贡献还是网络架构上。
3.DCGAN的核心架构是什么样?
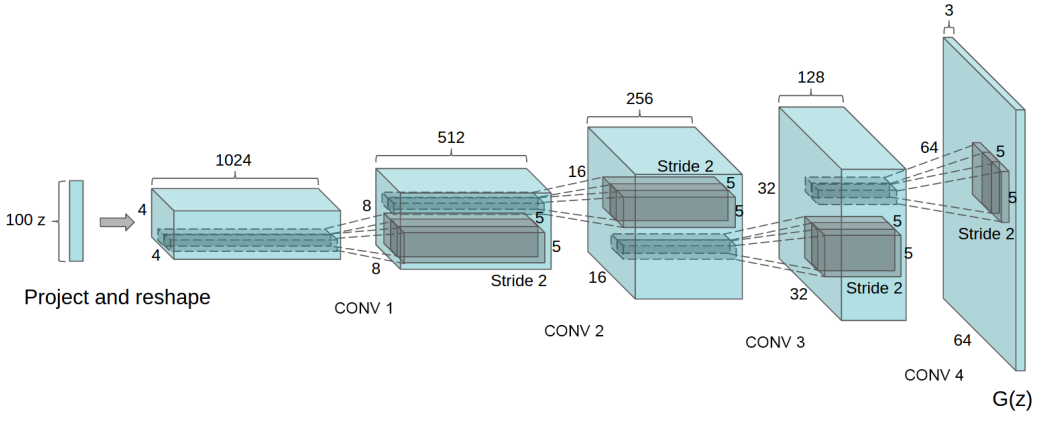
贴的是generator的网络架构,通过deconvolution(大多人认为是反卷积,其实并不正确)。关于discriminator的网络架构就比较简单,更符合正常的CNN架构,当然为了稳定训练,加了一些trick.
- 取消CNN的pooling layers
- generator和discriminator使用batchnorm。(今天特意查了一下batchnorm,发现跟自己想的有点差别,在文末会稍微解释一下)
- 去掉了fully connected hidden layers
- 对于generator,output使用Tanh,其它层使用RELU 激活函数
- 对于discriminator 使用LeakyRelu 激活函数
WGAN
废话
WGAN应该是我看的时长较长的一篇了,主要还是国庆边看边玩,再加上论文本身涉及的数学证明太多,居然还有拓扑学的知识,真是哔哔…最后还是自己菜。不能说完全理解了WGAN,但是精华部分算是了解了差不多了。
先说WGAN优点
WGAN的优点基本都是针对original GAN提出的。上面说的DCGAN主要从网络架构方面解决GAN的一些训练问题,但是治标不治本啊。WGAN的作者其实花了两篇文章来说明WGAN。第一篇主要’骂’了GAN,从GAN的’身世’开始’骂’。听说你想知道怎么’骂的’?来了。
- 解决训练不稳定问题(original GAN的通病)
- 解决collapse model,样本多样性缺失
- WGAN的loss能够指导模型训练
GAN的问题
Discriminator 不能训练的最好
GAN的论文中,generator的优化函数有两种形式
但是这种从函数可以看出,训练初期的梯度非常小,于是给出了另一种优化函数,能解决刚开始梯度很小的问题。
先说第一种的情况下
在GAN中,给出这样的最小最大优化公式。固定G,训练D,使得V取得最大值,将当前最优的D*带入V,可得到两分布之间的divergence,再求V的最小值等价于最小化两分布的误差。给出D*最大化的结果:那么问题来了,JS divergence能发挥作用的情况是当两分布有可用重叠部分,而在分布无重叠时JS=log2。那么两分布存在重叠的部分会有多大呢,作者在第一篇论文中从拓扑学的角度说明了:当P_r与P_g的支撑集(support)是高维空间中的低维流行(manifold),那么他们重叠部分测度为0的概率为1。也就是说P_r和P_g其实很难存在有用的重叠,那么无论分布远近,JS divergence永远是log2,导致生成器的梯度为0。有了上面初步分析,可以大概知道为什么GAN那么难训练了。Discriminator 训练的太好,generator的梯度消失,loss降不下去。训练的不好,无法指导generator训练,那就需要找到一个Discriminator训练的不好不差,这个很难去把握。
对于第二种,直接给出最后的等价形式,关于怎么来的,可参考这篇
$KL(P_g||P_r)-2JS(P_r||P_g)$
该表达式可以看出,既要最小化P_g和P_r之间的KLdivergence,又要最大化他们的JSdivergence,似乎有点矛盾。其次,KLdivergence并不是对称衡量,该式完整形式$KL(P_g||P_r)=P_g(x)log\frac{P_g(x)}{P_r(x)}$可以看出为了防止kl无穷大,生成器宁愿生成重复的样本,不愿生成缺乏多样性的样本,这种现象就是常见的collapse mode。
总结GAN的问题
- divergence 衡量方法不合理(KL,JS divergence)。
- 随机的生成分布与真实分布不可忽略的重叠少。
解决办法
- 加noise,将两个低维流行弥散到高维空间,强行产生有用的重叠,目标使JS发挥作用。
- 第一种方法治标不治本,没有从根源出发解决问题。Wasserstein 距离代替JS divergence,解决稳定训练问题,还能根据loss指示训练进程。
Wasserstein距离
关于Wasserstein的定义,,先截了网上一篇好的博客文章里的。
$\inf_{\gamma \sim \pi (P_r,P_g)}$是没法直接求解的。
先占坑,后面补
supplement
BatchNorm
在cv中,每一个batch数据都有不同的分布,当数据经过网络,它的数据分布也会发生变化(称为internal covariate shift)还有一个被称为covariate shift,描述的是训练数据和测试数据存在分的差异性。而batchnorm做的是归一化,对数据去相关性,加快训练速度,突出分布相对差异。 但是如果对每一层都做归一化是否可取呢?不然,假设每层都归一化到标准正太分布,可能会导致网络很难去学习输入数据的特征,想学的输入特征都被归一化了。Bathnorm算法提供了一种可训练参数归一化。 当$\gamma$为方差$\beta$为均值时,还原到输入。见详细原理代码可阅
当$\gamma$为方差$\beta$为均值时,还原到输入。见详细原理代码可阅