Pix2Pix
目前在做素描图片的生成,大概就是一张图片生成素描style。其实传统方法用二值化然后增加noise已经能够取得不错的效果(学姐就是这个做的,发了一篇B类的BestPaper)传统方法也会有一个问题:比如素描的阴影向量场的方向是固定的(传统方法生成需要给定一个方向)。想到用神经网络是否能够学习向量场,自动生成一张素描图片并带有丰富的阴影。有关神经网络生成模型:1.用CNN做风格迁移,一张图提取内容一张图提取颜色纹理。2.用GAN来生成图片主要就是conditional GAN了。本文所说的Pix2Pix是conditional GAN的一种了。
简单介绍
- Pix2Pix是一个图像翻译模型,训练的数据集必须一对(一个原始图片,一个生成图片),相对应的同一篇作者Cycle GAN。pix2pix原论文Image-to-Image Translation with Conditional Adversarial Networks。
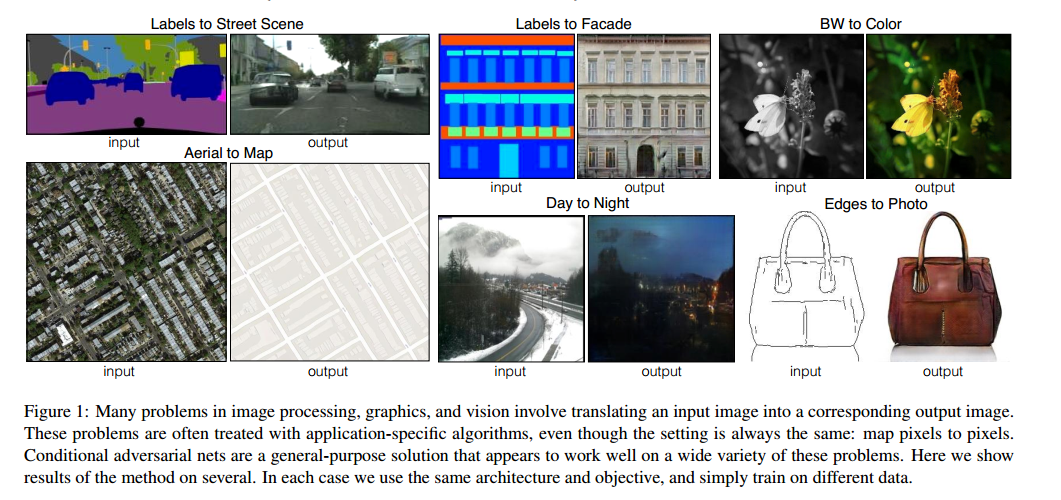
- 论文开头,作者说了该模型的优势:在图形学,图像处理中,一张图片到另一张图片的各种转换需要指定的算法,而pix2pix可以general-purpose。此处贴一张论文里面生成效果图片。
比较original GAN和conditional GAN
- original GAN学习的是将一个vector noize $z$,转化为image $y$。
- conditional GAN学习的是将一个vector noise $z$ + image $x$转为
- original GAN的objective function
- conditional GAN的objective function
- 关于两种的GAN的优化方法其实没有本质差异:$argmin_Gmax_DL_{cGAN}(G,D)$,先找到D*更新Discriminator的参数,在最小化$V(G,D*)$更新Generator的参数。
conditional GAN的小trick
多次试验,研究?反正就是说加入一些传统的loss在conditional GAN中往往能取得比较好的效果。从loss的公式也可以看出,loss能控制Generator生成的图片能够骗过Discriminator,还能控制生成的图片更能接近原图片。
那改进的conditional GAN的objective function变成了
Network architectures
Generator和Discriminator使用了convolution-BatchNorm-Relu的架构,论文里直接给了这样的架构,在写网络的时候清晰很多。
Generator with skips
- imageToimage问题:高分辨率的转换,input和output在surface appearance的差异。关于Generator网络结构很多,其中encoder-decoder网络:它是逐渐做下采样,到瓶颈层结束,然后反转做上采样。这会有一个问题,信息会传遍encoder-decoder的每一层包括瓶颈层,但是图片转换问题中,有很多low-level information在input和output之间是共享的需要直接传递,比如颜色,边缘的位置。
- 在pixtopix中Generator用的是U-net,可以解决信息的直接传递问题。共有n层,layer i层和n-i层是连接的。
上图比较清晰: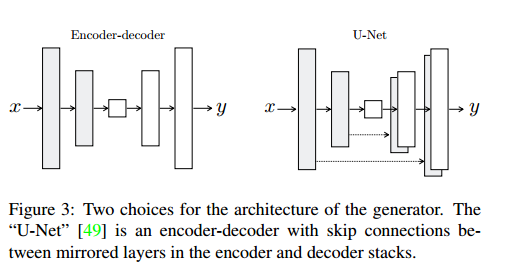
Discriminator (PatchGAN)
- 之前的研究实验表明L1 loss,L2 loss尽管生成的图像比较blurry,但是它们比较准确地抓住了low-frequency,那么我们整个框架就不需要全部学习了。
- 能够有方法让Discriminator只专注于high-frequency,而low-frequency则交给L1。如何专注于high-frequency,尽可能地去判别一些局部照片。实际操作,无论input多大,将其切分多个固定大小的Patch,输入Discriminator去判断。这样有一个很大的优势Discriminator的输入变小,计算量减小,运行速度快。