最近这段日子发现看论文好多看不懂,从Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks到同一作者的Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis.看完知道前者解决的问题是用Deep Markovian models做text synthesis带来的相当大的计算花费。后者做的是利用Markov Random Fields结合CNN做imgae Synthesis.虽然通读了下来,但是说到细节还是蒙圈的,主要问题出在概率图模型—Markov。这个本身就是难点,算是Markov在视觉上的应用。也大致了解了一些概率图知识,有点难入门。科研嘛,如果死脑筋,一直死磕会崩溃的。关于本篇想要解读的文章,是在上面两篇的文献中提到的,其实之前就很想了解,所以既然看不懂那两篇,就用这篇Visualizing and Understanding Convolutional Networks来调剂一哈吧,也许看完对CNN有一个新的认识。大概就是这么个心里路程!关于这篇我读的还挺细的,但是不打算系统的说明,就将其中的核心拎出来。
Visualization
CNN一直被人垢以‘黑盒’模型,很难从数学的角度完整地解释,但是一些研究者尝试通过模型的可视化探究CNN到底学了些什么?这里的可视化指的是Filter(卷积核)。可视化的工作分为两大类:
- 非参数化:指的是不分析CNN模型的参数,而是通过网络前向传播,对于指定的卷积核,可视化最大图片响应。本篇要说的可视化就是该类。
- 参数化:从参数出发,通过分析Filter的参数,使用参数构造图像。
Deconvnet
这篇论文探究的是在任意层中怎样的输入能够刺激产生feature map。具体的做法是:通过Deconvolutional Network将激活的feature反向映射到输入的像素空间。(这里的输入不是前层,而是input image。提醒一点的是:这里的Deconvolutional Network于作者之前发的Adative Deconvolutional Networks for Mid and High Level Feature Learning 里面提到的反卷积网络不同,本篇可视化论文只是作为prob来帮助理解CNN,没有非监督学习的任务。)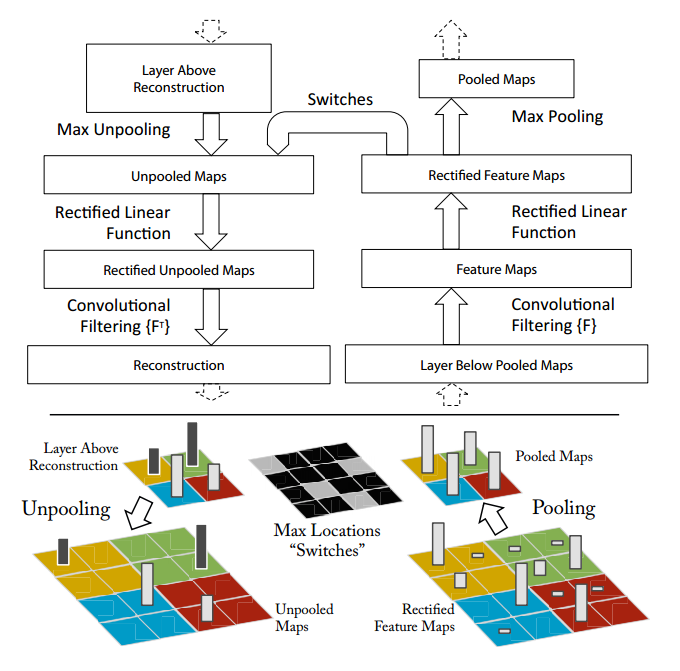
Deconvnet主要的三个操作
Unpooling
max pooling操作是不可逆的,但是可以选择近似逼近:通过一组switch变量来记录每一个pooling的最大值的位置。在deconvnet过程中,unpooling操作根据switch来重构Maps,如上图底部彩色信息部分。在作者之前的那篇非监督学习任务的Deconvnet网络中可以清楚看到unpooling是如何实现的。只不过当时用的三维池化操作。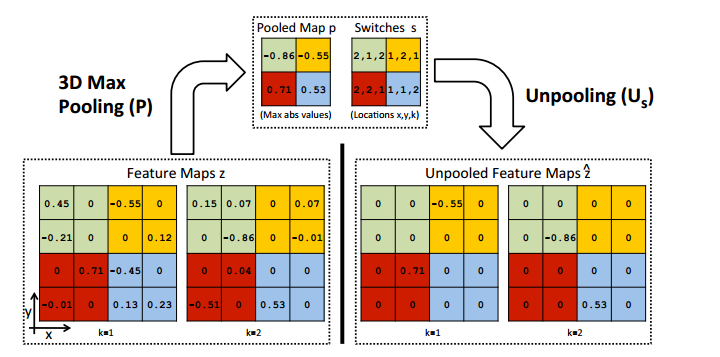
Rectification
Rectification控制feature maps总是正的,如果用的是relu非线性函数,那么他的逆过程仍然是relu,同样保证逆过程中每层feature reconstruction仍然是正的。
Filtering
这里主要说的是卷积的逆运算,deconvnet使用同样Filter的转置作为逆过程。
summarize Deconvnet
想要可视化每层学到的内容,需要从下往上依次计算,直到对应input pixl。例如想要layer5的可视化结果,经过layer4,layer3,layer2,layer1统统需要invert。作者把这个Deconvet的过程近似理解为backpropping一个strong activation。相当于计算$\frac{\partial h}{\partial X_n}$ $h$表示激活的feature map,$X_n$表示input image。
feature visualizatioon
对应每一层可视化的结果。
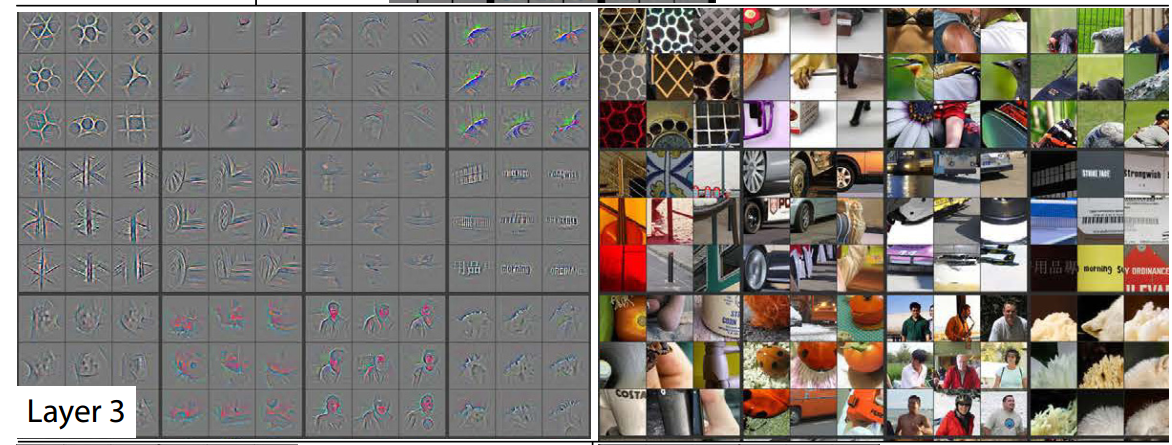

从可视化的结果我们大概知道了CNN的分层特性:第二层捕捉颜色纹理信息,第三层复杂的不变性,第四层展示了显著变化,类别开始具体,第五层显示了更加清晰的整个对象。
for what
有了可视化的结果,我们可以观察学习到的特征。从而改良模型。本文通过可视化发现浅层丢失了许多像素信息,AlexNet的基础上,缩小卷积核的尺寸和步长,立马超过了AlexNet的效果。除此之外,该方法探究卷积操作对平移缩放具有很好的不变性,而对于旋转的不变性较差。这方面能找到的内容还挺多的,基本就是CNN能取得好的效果的原因。
conclusion
大概就这样吧,虽然细节还是有一些模糊,但是总体大概就是这个样子。花了一天半时间弄完这篇论文,可视化不是我的重点,但是有一天如果想要回过头去进一步理解还是会回过头来看的。方向还是得明确,主要还是图像生成,主要还是用最近技术GAN,所以还是要多看看GAN的文章。